PostgreSQL is an object-relational database management system (ORDBMS) based on POSTGRES, Version 4.2, developed at the University of California at Berkeley Computer Science Department. POSTGRES pioneered many concepts that only became available in some commercial database systems much later.
PostgreSQL is an open-source descendant of this original Berkeley code. It supports SQL92 and SQL99 and offers many modern features: complex queries foreign keys triggers views transactional integrity multiversion concurrency control
Additionally, PostgreSQL can be extended by the user in many ways, for example by adding new data types functions operators aggregate functions index methods procedural languages
And because of the liberal license, PostgreSQL can be used, modified, and distributed by everyone free of charge for any purpose, be it private, commercial, or academic.
PostgreSQL - это свободно распространяемая объектно-реляционная система управления базами данных (ORDBMS), наиболее развитая из открытых СУБД в мире и являющаяся реальной альтернативой коммерческим базам данных. PostgreSQL произносится как post-gress-Q-L (можно скачать mp3 файл postgresql.mp3), в разговоре часто употребляется postgres (пост-гресс). Также, употребляется сокращение pgsql (пэ-жэ-эс-ку-эль).
История развития PostgreSQL
Краткую историю PostgreSQL можно прочитать в документации, распространяемой с дистрибутивом или на сайте. Также, есть перевод на русский язык. Из нее следует, что современный проект PostgreSQL ведет происхождение из проекта POSTGRES, который разрабатывался под руководством Майкла Стоунбрейкера (Michael Stonebraker), профессора Калифорнийского университета в Беркли (UCB). Мне захотелось несколько подробнее показать взаимосвязи родословных баз данных, чтобы лучше понять место PostgreSQL среди основных игроков современного рынка баз данных.
Я попытался графически ( большая версия картинки откроется в новом окне) отобразить все наиболее заметные RDBMS и связи между ними и приблизительно привел даты их создания и конца. Пересечение объектов означает поглощение, при этом поглощаемый объект более бледен и не окантован. Знак доллара означает, что база данных является коммерческой. При этом, я основывался на информации, доступной в интернете, в частности в Wikipedia, в научных статьях, которые я читал и комментариях непосредственных пользователей БД, которые я получил после публикации этой картинки в интернете.
Надо сказать, что несмотря на то, что вся история реляционных баз данных насчитывает менее 4 десятков лет, многие факты из истории создания трактуются по-разному, даты не согласуются, а сами участники событий зачастую просто вольно трактуют прошлое.Здесь надо принимать во внимание тот факт, что базы данных - это большой бизнес, в котором развитие одних БД часто связано с концом других. Кроме того, БД в то время были предметом научных исследований, поэтому приоритетность работ является не последним аргументом при написании воспоминаний и интервью. Наверное, учитывая такую запутанность, премия ACM Software System Award #6 была присуждена одновременно двум соперничающим группам исследователей из IBM за работу над "System R" и Беркли - за INGRES, хотя Стоунбрейкер получил награду от ACM SIGMOD (сейчас это премия названа в честь Теда Кодда - автора реляционной теории баз данных) #1 в 1992 г., а Грей (James Gray, Microsoft) - #2 в 1993 году.
Итак, как следует из рисунка, видно две ветви развития баз данных - одна следует из "System R", которая разрабатывалась в IBM в начале 70-х, и другая из проекта "INGRES", которым руководил Стоунбрейкер приблизительно в тоже время. Эти два проекта начались как необходимость практического использования реляционной модели баз данных, разработанной Тедом Коддом (Ted Codd) из IBM в 1969,1970 годах. Надо помнить, что в то время имелось две альтернативные модели баз данных - сетевая и иерархическая, причем за ними стояли мощные силы - CODASYL Data Base Task Group (сетевая) и сама IBM с ее базой IMS (Information Management System с иерархической моделью данных). Немного в стороне стоит "Oracle", взлет которой во многом связан с коммерческим талантом Эллисона быть в нужном месте и в нужное время, как сказал Стоунбрейкер в своем интервью, хотя она вместе с IBM сыграла большую роль в создании и продвижении SQL.
Международная команда разработчиков PostgreSQL объявила о выпуске PostgreSQL 8.1 — новой версии системы управления базами данных с открытым исходным кодом. По словам разработчиков, в новой версии улучшена производительность, реализованы расширенные средства SQL для поддержки больших хранилищ данных, обработки большого числа транзакций, а также более сложного распределенного корпоративного программного обеспечения. Новая PostgreSQL поддерживает роли, упрощая управление большим числом пользователей со сложными перекрывающимися наборами прав. Функции PostgreSQL теперь поддерживают параметры IN, OUT и INOUT, что улучшает поддержку сложной бизнес-логики для приложений J2EE и .NET. Введена двухфазная фиксация транзакций: необходимая для приложений в глобальных сетях и гетерогенных дата-центрах, использующих PostgreSQL, эта функция позволяет проведение ACID-совместимых транзакций среди распределенных серверов. Увеличение производительности в многопроцессорных системах (SMP): диспетчер буферизации в версии 8.1 был усовершенствован для практически линейного масштабирования с ростом числа процессоров, давая прирост производительности на 8-, 16-процессорных, двухъядерных и многоядерных системах. При необходимости индексы будут автоматически преобразованы в битовые маски в памяти, что дает двадцатикратное повышение производительности индексации на сложных запросах к большим таблицам. Это также упрощает управление базами данных, сокращая необходимость в мультистолбцовых индексах. Планировщик запросов может избегать сканирования целых секций большой таблицы, пользуясь техникой, известной как «исключение на основе ограничений». Сходная с «секционированием таблиц» других СУБД, эта возможность упрощает управление данными в многогигабайтных таблицах. Новая версия PostgreSQL поддерживает более высокий уровень параллелизма за счет добавления разделяемой блокировки строк для внешних ключей. Downloads (~11 Mb)_http://wwwmaster.post...-8.1.0.tar.bz2
ЭЖД, 7.12.2006 - 20:09
PostgreSQL 8.2
Вышла 8.2 версия PostgreSQL. Стоит отметить заявленное увеличение производительности на 20% ( согласно online transaction processing тестам ). Полный список изменений по ссылке. Downloads (~11,9 Mb)_http://wwwmaster.post...-8.2.0.tar.bz2
Доступна для загрузки новая версия свободной (распространяется под лицензией BSD) СУБД PostgreSQL, которая, к слову, используется на этом сайте с начала его существования.
Из списка измений можно отметить следующее: - Исправлено падение процесса в ситуации переполнения памяти при задании слишком большого значения в директиве log_min_error_statement. - Увеличена скорость добавления элементов в rtree индексы; - Устранены проблемы планировщика с OUTER JOIN; - В значениях типа "interval " теперь можно указывать одни миллисекунды или микросекунды; - Устранены проблемы в GIN индексах, используемых в /contrib/tsearch2; - Защита от преждевременного завершения работы REINDEX и CLUSTER при попытке обработки временных таблиц из другой сессии; - Для использования /contrib/dblink (функции для обращения к нескольким БД в рамках одного запроса) для непривилегированными пользователями теперь допустима только аутентификация по паролю; - Использование функций /contrib/pgstattuple отныне возможно только для привилегированных пользователей; - Многочисленные улучшения сокета для Windows.
PostgreSQL отличается исключительной надёжностью: согласно результатам автоматизированного исследования различного ПО на предмет ошибок (2005 г.), в исходном коде PostgreSQL было найдено 20 проблемных мест на 775 000 строк исходного кода (в среднем, одна ошибка на 39 000 строк кода). Для сравнения: MySQL — 97 проблем, одна ошибка на 4 000 строк кода. Downloads_http://wwwmaster.post...-8.2.5.tar.bz2
ЭЖД, 8.01.2008 - 17:21
PostgreSQL 8.2.6
» "Changes" «
Prevent functions in indexes from executing with the privileges of the user running VACUUM, ANALYZE, etc (Tom)
Functions used in index expressions and partial-index predicates are evaluated whenever a new table entry is made. It has long been understood that this poses a risk of trojan-horse code execution if one modifies a table owned by an untrustworthy user. (Note that triggers, defaults, check constraints, etc. pose the same type of risk.) But functions in indexes pose extra danger because they will be executed by routine maintenance operations such as VACUUM FULL, which are commonly performed automatically under a superuser account. For example, a nefarious user can execute code with superuser privileges by setting up a trojan-horse index definition and waiting for the next routine vacuum. The fix arranges for standard maintenance operations (including VACUUM, ANALYZE, REINDEX, and CLUSTER) to execute as the table owner rather than the calling user, using the same privilege-switching mechanism already used for SECURITY DEFINER functions. To prevent bypassing this security measure, execution of SET SESSION AUTHORIZATION and SET ROLE is now forbidden within a SECURITY DEFINER context. (CVE-2007-6600)
Repair assorted bugs in the regular-expression package (Tom, Will Drewry)
Suitably crafted regular-expression patterns could cause crashes, infinite or near-infinite looping, and/or massive memory consumption, all of which pose denial-of-service hazards for applications that accept regex search patterns from untrustworthy sources. (CVE-2007-4769, CVE-2007-4772, CVE-2007-6067)
Require non-superusers who use /contrib/dblink to use only password authentication, as a security measure (Joe)
The fix that appeared for this in 8.2.5 was incomplete, as it plugged the hole for only some dblink functions. (CVE-2007-6601, CVE-2007-3278)
Fix bugs in WAL replay for GIN indexes (Teodor)
Fix GIN index build to work properly when maintenance_work_mem is 4GB or more (Tom)
Update time zone data files to tzdata release 2007k (in particular, recent Argentina changes) (Tom)
Improve planner's handling of LIKE/regex estimation in non-C locales (Tom)
Fix planning-speed problem for deep outer-join nests, as well as possible poor choice of join order (Tom)
Fix planner failure in some cases of WHERE false AND var IN (SELECT ...) (Tom)
Make CREATE TABLE ... SERIAL and ALTER SEQUENCE ... OWNED BY not change the currval() state of the sequence (Tom)
Preserve the tablespace and storage parameters of indexes that are rebuilt by ALTER TABLE ... ALTER COLUMN TYPE (Tom)
Make archive recovery always start a new WAL timeline, rather than only when a recovery stop time was used (Simon)
This avoids a corner-case risk of trying to overwrite an existing archived copy of the last WAL segment, and seems simpler and cleaner than the original definition.
Make VACUUM not use all of maintenance_work_mem when the table is too small for it to be useful (Alvaro)
Fix potential crash in translate() when using a multibyte database encoding (Tom)
Make corr() return the correct result for negative correlation values (Neil)
Fix overflow in extract(epoch from interval) for intervals exceeding 68 years (Tom)
Fix PL/Perl to not fail when a UTF-8 regular expression is used in a trusted function (Andrew)
Fix PL/Perl to cope when platform's Perl defines type bool as int rather than char (Tom)
While this could theoretically happen anywhere, no standard build of Perl did things this way ... until Mac OS X 10.5.
Fix PL/Python to work correctly with Python 2.5 on 64-bit machines (Marko Kreen)
Fix PL/Python to not crash on long exception messages (Alvaro)
Fix pg_dump to correctly handle inheritance child tables that have default expressions different from their parent's (Tom)
Fix libpq crash when PGPASSFILE refers to a file that is not a plain file (Martin Pitt)
ecpg parser fixes (Michael)
Make contrib/pgcrypto defend against OpenSSL libraries that fail on keys longer than 128 bits; which is the case at least on some Solaris versions (Marko Kreen)
Make contrib/tablefunc's crosstab() handle NULL rowid as a category in its own right, rather than crashing (Joe)
Fix tsvector and tsquery output routines to escape backslashes correctly (Teodor, Bruce)
Fix crash of to_tsvector() on huge input strings (Teodor)
Require a specific version of Autoconf to be used when re-generating the configure script (Peter)
This affects developers and packagers only. The change was made to prevent accidental use of untested combinations of Autoconf and PostgreSQL versions. You can remove the version check if you really want to use a different Autoconf version, but it's your responsibility whether the result works or not.
Update gettimeofday configuration check so that PostgreSQL can be built on newer versions of MinGW (Magnus)
* миграция модуля для полнотекстового поиска (contrib/tsearch2) в ядро системы; * реализация Heap Only Tuples (HOT); * теперь autovacuum включён по умолчанию; * возможнен запуск сразу нескольких процессов autovacuum; * заметное уменьшение дискового пространства, занимаемого базами данных; * выполнение транзакций, не модифицирующих данные, не приводит к увеличению значения счётчика транзакций (xid); * реализован механизм автонастройки параметров процесса bgwriter; * оптимизирован механизм получения результата для запросов с использованием « …ORDER BY … LIMIT…» (т. н., Top-N sorting); * поддержка XML, в том числе новый тип данных - xml; * автоматическая инвалидация кэша плана запросов для PL/pgSQL-функций; * конструкции «CREATE FUNCTION … RETURNS TABLE» и «RETURN TABLE…» для создания функций, результатом которых является таблица; * поддержка операции обновления для курсоров; * стандартная (ISO/ANSI SQL) конструкция «ORDER BY … NULLS FIRST/LAST» для упрощения установки порядка следования NULL-значений (также помогает при миграции с других СУБД); * индексация NULL-значений в GiST-индексах.
» "Notes" «
E.1. Release 8.3
Release date: 2008-02-04 E.1.1. Overview
With significant new functionality and performance enhancements, this release represents a major leap forward for PostgreSQL. This was made possible by a growing community that has dramatically accelerated the pace of development. This release adds the following major features:
Full text search is integrated into the core database system
Support for the SQL/XML standard, including new operators and an XML data type
Enumerated data types (ENUM)
Arrays of composite types
Universally Unique Identifier (UUID) data type
Add control over whether NULLs sort first or last
Updatable cursors
Server configuration parameters can now be set on a per-function basis
User-defined types can now have type modifiers
Automatically re-plan cached queries when table definitions change or statistics are updated
Numerous improvements in logging and statistics collection
Support Security Service Provider Interface (SSPI) for authentication on Windows
Support multiple concurrent autovacuum processes, and other autovacuum improvements
Allow the whole PostgreSQL distribution to be compiled with Microsoft Visual C++
Major performance improvements are listed below. Most of these enhancements are automatic and do not require user changes or tuning:
Asynchronous commit delays writes to WAL during transaction commit
Checkpoint writes can be spread over a longer time period to smooth the I/O spike during each checkpoint
Heap-Only Tuples (HOT) accelerate space reuse for most UPDATEs and DELETEs
Just-in-time background writer strategy improves disk write efficiency
Using non-persistent transaction IDs for read-only transactions reduces overhead and VACUUM requirements
Per-field and per-row storage overhead has been reduced
Large sequential scans no longer force out frequently used cached pages
Concurrent large sequential scans can now share disk reads
ORDER BY ... LIMIT can be done without sorting
The above items are explained in more detail in the sections below. E.1.2. Migration to Version 8.3
A dump/restore using pg_dump is required for those wishing to migrate data from any previous release.
Observe the following incompatibilities: E.1.2.1. General
Non-character data types are no longer automatically cast to TEXT (Peter, Tom)
Previously, if a non-character value was supplied to an operator or function that requires text input, it was automatically cast to text, for most (though not all) built-in data types. This no longer happens: an explicit cast to text is now required for all non-character-string types. For example, these expressions formerly worked: substr(current_date, 1, 4) 23 LIKE '2%'
but will now draw "function does not exist" and "operator does not exist" errors respectively. Use an explicit cast instead: substr(current_date::text, 1, 4) 23::text LIKE '2%'
(Of course, you can use the more verbose CAST() syntax too.) The reason for the change is that these automatic casts too often caused surprising behavior. An example is that in previous releases, this expression was accepted but did not do what was expected: current_date < 2017-11-17
This is actually comparing a date to an integer, which should be (and now is) rejected — but in the presence of automatic casts both sides were cast to text and a textual comparison was done, because the text < text operator was able to match the expression when no other < operator could.
Types char(n) and varchar(n) still cast to text automatically. Also, automatic casting to text still works for inputs to the concatenation (||) operator, so long as least one input is a character-string type.
Full text search features from contrib/tsearch2 have been moved into the core server, with some minor syntax changes
contrib/tsearch2 now contains a compatibility interface.
ARRAY(SELECT ...), where the SELECT returns no rows, now returns an empty array, rather than NULL (Tom)
The array type name for a base data type is no longer always the base type's name with an underscore prefix
The old naming convention is still honored when possible, but application code should no longer depend on it. Instead use the new pg_type.typarray column to identify the array data type associated with a given type.
ORDER BY ... USING operator must now use a less-than or greater-than operator that is defined in a btree operator class
This restriction was added to prevent inconsistent results.
SET LOCAL changes now persist until the end of the outermost transaction, unless rolled back (Tom)
Previously SET LOCAL's effects were lost after subtransaction commit (RELEASE SAVEPOINT or exit from a PL/pgSQL exception block).
Commands rejected in transaction blocks are now also rejected in multiple-statement query strings (Tom)
For example, "BEGIN; DROP DATABASE; COMMIT" will now be rejected even if submitted as a single query message.
ROLLBACK outside a transaction block now issues NOTICE instead of WARNING (Bruce)
Prevent NOTIFY/LISTEN/UNLISTEN from accepting schema-qualified names (Bruce)
Formerly, these commands accepted schema.relation but ignored the schema part, which was confusing.
ALTER SEQUENCE no longer affects the sequence's currval() state (Tom)
Foreign keys now must match indexable conditions for cross-data-type references (Tom)
This improves semantic consistency and helps avoid performance problems.
Restrict object size functions to users who have reasonable permissions to view such information (Tom)
For example, pg_database_size() now requires CONNECT permission, which is granted to everyone by default. pg_tablespace_size() requires CREATE permission in the tablespace, or is allowed if the tablespace is the default tablespace for the database.
Remove the undocumented !!= (not in) operator (Tom)
NOT IN (SELECT ...) is the proper way to perform this operation.
Internal hashing functions are now more uniformly-distributed (Tom)
If application code was computing and storing hash values using internal PostgreSQL hashing functions, the hash values must be regenerated.
C-code conventions for handling variable-length data values have changed (Greg Stark, Tom)
The new SET_VARSIZE() macro must be used to set the length of generated varlena values. Also, it might be necessary to expand ("de-TOAST") input values in more cases.
Continuous archiving no longer reports each successful archive operation to the server logs unless DEBUG level is used (Simon) E.1.2.2. Configuration Parameters
Numerous changes in administrative server parameters
bgwriter_lru_percent, bgwriter_all_percent, bgwriter_all_maxpages, stats_start_collector, and stats_reset_on_server_start are removed. redirect_stderr is renamed to logging_collector. stats_command_string is renamed to track_activities. stats_block_level and stats_row_level are merged into track_counts. A new boolean configuration parameter, archive_mode, controls archiving. Autovacuum's default settings have changed.
Remove stats_start_collector parameter (Tom)
We now always start the collector process, unless UDP socket creation fails.
This was removed because pg_stat_reset() can be used for this purpose.
Commenting out a parameter in postgresql.conf now causes it to revert to its default value (Joachim Wieland)
Previously, commenting out an entry left the parameter's value unchanged until the next server restart. E.1.2.3. Character Encodings
Add more checks for invalidly-encoded data (Andrew)
This change plugs some holes that existed in literal backslash escape string processing and COPY escape processing. Now the de-escaped string is rechecked to see if the result created an invalid multi-byte character.
Disallow database encodings that are inconsistent with the server's locale setting (Tom)
On most platforms, C locale is the only locale that will work with any database encoding. Other locale settings imply a specific encoding and will misbehave if the database encoding is something different. (Typical symptoms include bogus textual sort order and wrong results from upper() or lower().) The server now rejects attempts to create databases that have an incompatible encoding.
Ensure that chr() cannot create invalidly-encoded values (Andrew)
In UTF8-encoded databases the argument of chr() is now treated as a Unicode code point. In other multi-byte encodings chr()'s argument must designate a 7-bit ASCII character. Zero is no longer accepted. ascii() has been adjusted to match.
Adjust convert() behavior to ensure encoding validity (Andrew)
The two argument form of convert() has been removed. The three argument form now takes a bytea first argument and returns a bytea. To cover the loss of functionality, three new functions have been added:
convert_from(bytea, name) returns text — converts the first argument from the named encoding to the database encoding
convert_to(text, name) returns bytea — converts the first argument from the database encoding to the named encoding
length(bytea, name) returns integer — gives the length of the first argument in characters in the named encoding
Remove convert(argument USING conversion_name) (Andrew)
Its behavior did not match the SQL standard.
Make JOHAB encoding client-only (Tatsuo)
JOHAB is not safe as a server-side encoding. E.1.3. Changes
Below you will find a detailed account of the changes between PostgreSQL 8.3 and the previous major release. E.1.3.1. Performance
Asynchronous commit delays writes to WAL during transaction commit (Simon)
This feature dramatically increases performance for short data-modifying transactions. The disadvantage is that because disk writes are delayed, if the operating system crashes before data is written to the disk, committed data will be lost. This feature is useful for applications that can accept some data loss. Unlike turning off fsync, asynchronous commit does not put database consistency at risk; the worst case is that after a database or system crash the last few reportedly-committed transactions might be missing. This feature is enabled by turning off synchronous_commit (which can be done per-session or per-transaction, if some transactions are critical and others are not). wal_writer_delay can be adjusted to control the maximum delay before transactions actually reach disk.
Checkpoint writes can be spread over a longer time period to smooth the I/O spike during each checkpoint (Itagaki Takahiro and Heikki Linnakangas)
Previously all modified buffers were forced to disk as quickly as possible during a checkpoint, causing an I/O spike that decreased server performance. This new approach spreads out disk writes during checkpoints, reducing peak I/O usage. (User-requested and shutdown checkpoints are still written as quickly as possible.)
Heap-Only Tuples (HOT) accelerate space reuse for most UPDATEs and DELETEs (Pavan Deolasee, with ideas from many others)
UPDATEs and DELETEs leave dead tuples behind, as do failed INSERTs. Previously only VACUUM could reclaim space taken by dead tuples. With HOT dead tuple space can be reclaimed at the time of INSERT or UPDATE if no changes are made to indexed columns. This allows for more consistent performance. Also, HOT avoids adding duplicate index entries.
This greatly reduces the need for manual tuning of the background writer.
Per-field and per-row storage overhead have been reduced (Greg Stark, Heikki Linnakangas)
Variable-length data types with data values less than 128 bytes long will see a storage decrease of 3 to 6 bytes. For example, two adjacent char(1) fields now use 4 bytes instead of 16. Row headers are also 4 bytes shorter than before.
Using non-persistent transaction IDs for read-only transactions reduces overhead and VACUUM requirements (Florian Pflug)
Non-persistent transaction IDs do not increment the global transaction counter. Therefore, they reduce the load on pg_clog and increase the time between forced vacuums to prevent transaction ID wraparound. Other performance improvements were also made that should improve concurrency.
Avoid incrementing the command counter after a read-only command (Tom)
There was formerly a hard limit of 232 (4 billion) commands per transaction. Now only commands that actually changed the database count, so while this limit still exists, it should be significantly less annoying.
Create a dedicated WAL writer process to off-load work from backends (Simon)
Skip unnecessary WAL writes for CLUSTER and COPY (Simon)
Unless WAL archiving is enabled, the system now avoids WAL writes for CLUSTER and just fsync()s the table at the end of the command. It also does the same for COPY if the table was created in the same transaction.
Large sequential scans no longer force out frequently used cached pages (Simon, Heikki, Tom)
Concurrent large sequential scans can now share disk reads (Jeff Davis)
This is accomplished by starting the new sequential scan in the middle of the table (where another sequential scan is already in-progress) and wrapping around to the beginning to finish. This can affect the order of returned rows in a query that does not specify ORDER BY. The synchronize_seqscans configuration parameter can be used to disable this if necessary.
ORDER BY ... LIMIT can be done without sorting (Greg Stark)
This is done by sequentially scanning the table and tracking just the "top N" candidate rows, rather than performing a full sort of the entire table. This is useful when there is no matching index and the LIMIT is not large.
Put a rate limit on messages sent to the statistics collector by backends (Tom)
This reduces overhead for short transactions, but might sometimes increase the delay before statistics are tallied.
Improve hash join performance for cases with many NULLs (Tom)
Speed up operator lookup for cases with non-exact datatype matches (Tom) E.1.3.2. Server
Autovacuum is now enabled by default (Alvaro)
Several changes were made to eliminate disadvantages of having autovacuum enabled, thereby justifying the change in default. Several other autovacuum parameter defaults were also modified.
Support multiple concurrent autovacuum processes (Alvaro, Itagaki Takahiro)
This allows multiple vacuums to run concurrently. This prevents vacuuming of a large table from delaying vacuuming of smaller tables.
Automatically re-plan cached queries when table definitions change or statistics are updated (Tom)
Previously PL/PgSQL functions that referenced temporary tables would fail if the temporary table was dropped and recreated between function invocations, unless EXECUTE was used. This improvement fixes that problem and many related issues.
Add a temp_tablespaces parameter to control the tablespaces for temporary tables and files (Jaime Casanova, Albert Cervera, Bernd Helmle)
This parameter defines a list of tablespaces to be used. This enables spreading the I/O load across multiple tablespaces. A random tablespace is chosen each time a temporary object is created. Temporary files are no longer stored in per-database pgsql_tmp/ directories but in per-tablespace directories.
Place temporary tables' TOAST tables in special schemas named pg_toast_temp_nnn (Tom)
This allows low-level code to recognize these tables as temporary, which enables various optimizations such as not WAL-logging changes and using local rather than shared buffers for access. This also fixes a bug wherein backends unexpectedly held open file references to temporary TOAST tables.
Fix problem that a constant flow of new connection requests could indefinitely delay the postmaster from completing a shutdown or a crash restart (Tom)
Guard against a very-low-probability data loss scenario by preventing re-use of a deleted table's relfilenode until after the next checkpoint (Heikki)
Fix CREATE CONSTRAINT TRIGGER to convert old-style foreign key trigger definitions into regular foreign key constraints (Tom)
This will ease porting of foreign key constraints carried forward from pre-7.3 databases, if they were never converted using contrib/adddepend.
Fix DEFAULT NULL to override inherited defaults (Tom)
DEFAULT NULL was formerly considered a noise phrase, but it should (and now does) override non-null defaults that would otherwise be inherited from a parent table or domain.
Add new encodings EUC_JIS_2004 and SHIFT_JIS_2004 (Tatsuo)
These new encodings can be converted to and from UTF-8.
Change server startup log message from "database system is ready" to "database system is ready to accept connections", and adjust its timing
The message now appears only when the postmaster is really ready to accept connections. E.1.3.3. Monitoring
Add log_autovacuum_min_duration parameter to support configurable logging of autovacuum activity (Simon, Alvaro)
Add log_lock_waits parameter to log lock waiting (Simon)
Add log_temp_files parameter to log temporary file usage (Bill Moran)
Add log_checkpoints parameter to improve logging of checkpoints (Greg Smith, Heikki)
log_line_prefix now supports %s and %c escapes in all processes (Andrew)
Previously these escapes worked only for user sessions, not for background database processes.
Add log_restartpoints to control logging of point-in-time recovery restart points (Simon)
Last transaction end time is now logged at end of recovery and at each logged restart point (Simon)
Autovacuum now reports its activity start time in pg_stat_activity (Tom)
Allow server log output in comma-separated value (CSV) format (Arul Shaji, Greg Smith, Andrew Dunstan)
CSV-format log files can easily be loaded into a database table for subsequent analysis.
Use PostgreSQL-supplied timezone support for formatting timestamps displayed in the server log (Tom)
This avoids Windows-specific problems with localized time zone names that are in the wrong encoding. There is a new log_timezone parameter that controls the timezone used in log messages, independently of the client-visible timezone parameter.
New system view pg_stat_bgwriter displays statistics about background writer activity (Magnus)
Add new columns for database-wide tuple statistics to pg_stat_database (Magnus)
Add an xact_start (transaction start time) column to pg_stat_activity (Neil)
This makes it easier to identify long-running transactions.
Add n_live_tuples and n_dead_tuples columns to pg_stat_all_tables and related views (Glen Parker)
Merge stats_block_level and stats_row_level parameters into a single parameter track_counts, which controls all messages sent to the statistics collector process (Tom)
Rename stats_command_string parameter to track_activities (Tom)
Fix statistical counting of live and dead tuples to recognize that committed and aborted transactions have different effects (Tom) E.1.3.4. Authentication
Support Security Service Provider Interface (SSPI) for authentication on Windows (Magnus)
Support GSSAPI authentication (Henry Hotz, Magnus)
This should be preferred to native Kerberos authentication because GSSAPI is an industry standard.
Support a global SSL configuration file (Victor Wagner)
Add ssl_ciphers parameter to control accepted SSL ciphers (Victor Wagner)
Add a Kerberos realm parameter, krb_realm (Magnus) E.1.3.5. Write-Ahead Log (WAL) and Continuous Archiving
Change the timestamps recorded in transaction WAL records from time_t to TimestampTz representation (Tom)
This provides sub-second resolution in WAL, which can be useful for point-in-time recovery.
Reduce WAL disk space needed by warm standby servers (Simon)
This change allows a warm standby server to pass the name of the earliest still-needed WAL file to the recovery script, allowing automatic removal of no-longer-needed WAL files. This is done using %r in the restore_command parameter of recovery.conf.
New boolean configuration parameter, archive_mode, controls archiving (Simon)
Previously setting archive_command to an empty string turned off archiving. Now archive_mode turns archiving on and off, independently of archive_command. This is useful for stopping archiving temporarily. E.1.3.6. Queries
Full text search is integrated into the core database system (Teodor, Oleg)
Text search has been improved, moved into the core code, and is now installed by default. contrib/tsearch2 now contains a compatibility interface.
Add control over whether NULLs sort first or last (Teodor, Tom)
The syntax is ORDER BY ... NULLS FIRST/LAST.
Allow per-column ascending/descending (ASC/DESC) ordering options for indexes (Teodor, Tom)
Previously a query using ORDER BY with mixed ASC/DESC specifiers could not fully use an index. Now an index can be fully used in such cases if the index was created with matching ASC/DESC specifications. NULL sort order within an index can be controlled, too.
Allow col IS NULL to use an index (Teodor)
Updatable cursors (Arul Shaji, Tom)
This eliminates the need to reference a primary key to UPDATE or DELETE rows returned by a cursor. The syntax is UPDATE/DELETE WHERE CURRENT OF.
Allow FOR UPDATE in cursors (Arul Shaji, Tom)
Create a general mechanism that supports casts to and from the standard string types (TEXT, VARCHAR, CHAR) for every datatype, by invoking the datatype's I/O functions (Tom)
Previously, such casts were available only for types that had specialized function(s) for the purpose. These new casts are assignment-only in the to-string direction, explicit-only in the other direction, and therefore should create no surprising behavior.
Allow UNION and related constructs to return a domain type, when all inputs are of that domain type (Tom)
Formerly, the output would be considered to be of the domain's base type.
Allow limited hashing when using two different data types (Tom)
This allows hash joins, hash indexes, hashed subplans, and hash aggregation to be used in situations involving cross-data-type comparisons, if the data types have compatible hash functions. Currently, cross-data-type hashing support exists for smallint/integer/bigint, and for float4/float8.
Improve optimizer logic for detecting when variables are equal in a WHERE clause (Tom)
This allows mergejoins to work with descending sort orders, and improves recognition of redundant sort columns.
Improve performance when planning large inheritance trees in cases where most tables are excluded by constraints (Tom) E.1.3.7. Object Manipulation
Arrays of composite types (David Fetter, Andrew, Tom)
In addition to arrays of explicitly-declared composite types, arrays of the rowtypes of regular tables and views are now supported, except for rowtypes of system catalogs, sequences, and TOAST tables.
Server configuration parameters can now be set on a per-function basis (Tom)
For example, functions can now set their own search_path to prevent unexpected behavior if a different search_path exists at run-time. Security definer functions should set search_path to avoid security loopholes.
CREATE/ALTER FUNCTION now supports COST and ROWS options (Tom)
COST allows specification of the cost of a function call. ROWS allows specification of the average number or rows returned by a set-returning function. These values are used by the optimizer in choosing the best plan.
Implement CREATE TABLE LIKE ... INCLUDING INDEXES (Trevor Hardcastle, Nikhil Sontakke, Neil)
Allow CREATE INDEX CONCURRENTLY to ignore transactions in other databases (Simon)
Add ALTER VIEW ... RENAME TO and ALTER SEQUENCE ... RENAME TO (David Fetter, Neil)
Previously this could only be done via ALTER TABLE ... RENAME TO.
Make CREATE/DROP/RENAME DATABASE wait briefly for conflicting backends to exit before failing (Tom)
This increases the likelihood that these commands will succeed.
Allow triggers and rules to be deactivated in groups using a configuration parameter, for replication purposes (Jan)
This allows replication systems to disable triggers and rewrite rules as a group without modifying the system catalogs directly. The behavior is controlled by ALTER TABLE and a new parameter session_replication_role.
User-defined types can now have type modifiers (Teodor, Tom)
This allows a user-defined type to take a modifier, like ssnum(7). Previously only built-in data types could have modifiers. E.1.3.8. Utility Commands
Non-superuser database owners now are able to add trusted procedural languages to their databases by default (Jeremy Drake)
While this is reasonably safe, some administrators might wish to revoke the privilege. It is controlled by pg_pltemplate.tmpldbacreate.
Allow a session's current parameter setting to be used as the default for future sessions (Tom)
This is done with SET ... FROM CURRENT in CREATE/ALTER FUNCTION, ALTER DATABASE, or ALTER ROLE.
Implement new commands DISCARD ALL, DISCARD PLANS, DISCARD TEMPORARY, CLOSE ALL, and DEALLOCATE ALL (Marko Kreen, Neil)
These commands simplify resetting a database session to its initial state, and are particularly useful for connection-pooling software.
Make CLUSTER MVCC-safe (Heikki Linnakangas)
Formerly, CLUSTER would discard all tuples that were committed dead, even if there were still transactions that should be able to see them under MVCC visibility rules.
Add new CLUSTER syntax: CLUSTER table USING index (Holger Schurig)
The old CLUSTER syntax is still supported, but the new form is considered more logical.
Fix EXPLAIN so it can show complex plans more accurately (Tom)
References to subplan outputs are now always shown correctly, instead of using ?columnN? for complicated cases.
Limit the amount of information reported when a user is dropped (Alvaro)
Previously, dropping (or attempting to drop) a user who owned many objects could result in large NOTICE or ERROR messages listing all these objects; this caused problems for some client applications. The length of the message is now limited, although a full list is still sent to the server log. E.1.3.9. Data Types
Support for the SQL/XML standard, including new operators and an XML data type (Nikolay Samokhvalov, Pavel Stehule, Peter)
Enumerated data types (ENUM) (Tom Dunstan)
This feature provides convenient support for fields that have a small, fixed set of allowed values. An example of creating an ENUM type is CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy').
Universally Unique Identifier (UUID) data type (Gevik Babakhani, Neil)
This closely matches RFC 4122.
Widen the MONEY data type to 64 bits (D'Arcy Cain)
This greatly increases the range of supported MONEY values.
Fix float4/float8 to handle Infinity and NAN (Not A Number) consistently (Bruce)
The code formerly was not consistent about distinguishing Infinity from overflow conditions.
Allow leading and trailing whitespace during input of boolean values (Neil)
Prevent COPY from using digits and lowercase letters as delimiters (Tom) E.1.3.10. Functions
Add new regular expression functions regexp_matches(), regexp_split_to_array(), and regexp_split_to_table() (Jeremy Drake, Neil)
These functions provide extraction of regular expression subexpressions and allow splitting a string using a POSIX regular expression.
Add lo_truncate() for large object truncation (Kris Jurka)
Implement width_bucket() for the float8 data type (Neil)
Add pg_stat_clear_snapshot() to discard statistics snapshots collected during the current transaction (Tom)
The first request for statistics in a transaction takes a statistics snapshot that does not change during the transaction. This function allows the snapshot to be discarded and a new snapshot loaded during the next statistics query. This is particularly useful for PL/PgSQL functions, which are confined to a single transaction.
Add isodow option to EXTRACT() and date_part() (Bruce)
This returns the day of the week, with Sunday as seven. (dow returns Sunday as zero.)
Add ID (ISO day of week) and IDDD (ISO day of year) format codes for to_char(), to_date(), and to_timestamp() (Brendan Jurd)
Make to_timestamp() and to_date() assume TM (trim) option for potentially variable-width fields (Bruce)
This matches Oracle's behavior.
Fix off-by-one conversion error in to_date()/to_timestamp() D (non-ISO day of week) fields (Bruce)
Make setseed() return void, rather than a useless integer value (Neil)
Add a hash function for NUMERIC (Neil)
This allows hash indexes and hash-based plans to be used with NUMERIC columns.
Improve efficiency of LIKE/ILIKE, especially for multi-byte character sets like UTF-8 (Andrew, Itagaki Takahiro)
Make currtid() functions require SELECT privileges on the target table (Tom)
Add several txid_*() functions to query active transaction IDs (Jan)
This is useful for various replication solutions. E.1.3.11. PL/PgSQL Server-Side Language
Add scrollable cursor support, including directional control in FETCH (Pavel Stehule)
Allow IN as an alternative to FROM in PL/PgSQL's FETCH statement, for consistency with the backend's FETCH command (Pavel Stehule)
Add MOVE to PL/PgSQL (Magnus, Pavel Stehule, Neil)
Implement RETURN QUERY (Pavel Stehule, Neil)
This adds convenient syntax for PL/PgSQL set-returning functions that want to return the result of a query. RETURN QUERY is easier and more efficient than a loop around RETURN NEXT.
Allow function parameter names to be qualified with the function's name (Tom)
For example, myfunc.myvar. This is particularly useful for specifying variables in a query where the variable name might match a column name.
Make qualification of variables with block labels work properly (Tom)
Formerly, outer-level block labels could unexpectedly interfere with recognition of inner-level record or row references.
Tighten requirements for FOR loop STEP values (Tom)
Prevent non-positive STEP values, and handle loop overflows.
Improve accuracy when reporting syntax error locations (Tom) E.1.3.12. Other Server-Side Languages
Allow type-name arguments to PL/Perl spi_prepare() to be data type aliases in addition to names found in pg_type (Andrew)
Allow type-name arguments to PL/Python plpy.prepare() to be data type aliases in addition to names found in pg_type (Andrew)
Allow type-name arguments to PL/Tcl spi_prepare to be data type aliases in addition to names found in pg_type (Andrew)
Enable PL/PythonU to compile on Python 2.5 (Marko Kreen)
Support a true PL/Python boolean type in compatible Python versions (Python 2.3 and later) (Marko Kreen)
Fix PL/Tcl problems with thread-enabled libtcl spawning multiple threads within the backend (Steve Marshall, Paul Bayer, Doug Knight)
This caused all sorts of unpleasantness. E.1.3.13. psql
List disabled triggers separately in \d output (Brendan Jurd)
In \d patterns, always match $ literally (Tom)
Show aggregate return types in \da output (Greg Sabino Mullane)
Add the function's volatility status to the output of \df+ (Neil)
Add \prompt capability (Chad Wagner)
Allow \pset, \t, and \x to specify on or off, rather than just toggling (Chad Wagner)
Add \sleep capability (Jan)
Enable \timing output for \copy (Andrew)
Improve \timing resolution on Windows (Itagaki Takahiro)
Flush \o output after each backslash command (Tom)
Correctly detect and report errors while reading a -f input file (Peter)
Remove -u option (this option has long been deprecated) (Tom) E.1.3.14. pg_dump
Add --tablespaces-only and --roles-only options to pg_dumpall (Dave Page)
Add an output file option to pg_dumpall (Dave Page)
This is primarily useful on Windows, where output redirection of child pg_dump processes does not work.
Allow pg_dumpall to accept an initial-connection database name rather than the default template1 (Dave Page)
In -n and -t switches, always match $ literally (Tom)
Improve performance when a database has thousands of objects (Tom)
Remove -u option (this option has long been deprecated) (Tom) E.1.3.15. Other Client Applications
In initdb, allow the location of the pg_xlog directory to be specified (Euler Taveira de Oliveira)
Enable server core dump generation in pg_regress on supported operating systems (Andrew)
Add a -t (timeout) parameter to pg_ctl (Bruce)
This controls how long pg_ctl will wait when waiting for server startup or shutdown. Formerly the timeout was hard-wired as 60 seconds.
Add a pg_ctl option to control generation of server core dumps (Andrew)
Allow Control-C to cancel clusterdb, reindexdb, and vacuumdb (Itagaki Takahiro, Magnus)
Suppress command tag output for createdb, createuser, dropdb, and dropuser (Peter)
The --quiet option is ignored and will be removed in 8.4. Progress messages when acting on all databases now go to stdout instead of stderr because they are not actually errors. E.1.3.16. libpq
Interpret the dbName parameter of PQsetdbLogin() as a conninfo string if it contains an equals sign (Andrew)
This allows use of conninfo strings in client programs that still use PQsetdbLogin().
Support a global SSL configuration file (Victor Wagner)
Add environment variable PGSSLKEY to control SSL hardware keys (Victor Wagner)
Add lo_truncate() for large object truncation (Kris Jurka)
Add PQconnectionNeedsPassword() that returns true if the server required a password but none was supplied (Joe Conway, Tom)
If this returns true after a failed connection attempt, a client application should prompt the user for a password. In the past applications have had to check for a specific error message string to decide whether a password is needed; that approach is now deprecated.
Add PQconnectionUsedPassword() that returns true if the supplied password was actually used (Joe Conway, Tom)
This is useful in some security contexts where it is important to know whether a user-supplied password is actually valid. E.1.3.17. ecpg
Use V3 frontend/backend protocol (Michael)
This adds support for server-side prepared statements.
Use native threads, instead of pthreads, on Windows (Magnus)
Improve thread-safety of ecpglib (Itagaki Takahiro)
Make the ecpg libraries export only necessary API symbols (Michael) E.1.3.18. Windows Port
Allow the whole PostgreSQL distribution to be compiled with Microsoft Visual C++ (Magnus and others)
This allows Windows-based developers to use familiar development and debugging tools. Windows executables made with Visual C++ might also have better stability and performance than those made with other tool sets. The client-only Visual C++ build scripts have been removed.
Drastically reduce postmaster's memory usage when it has many child processes (Magnus)
Allow regression tests to be started by an administrative user (Magnus)
Add cursor-related functionality in SPI (Pavel Stehule)
Allow access to the cursor-related planning options, and add FETCH/MOVE routines.
Allow execution of cursor commands through SPI_execute (Tom)
The macro SPI_ERROR_CURSOR still exists but will never be returned.
SPI plan pointers are now declared as SPIPlanPtr instead of void * (Tom)
This does not break application code, but switching is recommended to help catch simple programming mistakes. E.1.3.20. Build Options
Add configure option --enable-profiling to enable code profiling (works only with gcc) (Korry Douglas and Nikhil Sontakke)
Add configure option --with-system-tzdata to use the operating system's time zone database (Peter)
Fix PGXS so extensions can be built against PostgreSQL installations whose pg_config program does not appear first in the PATH (Tom)
Support gmake draft when building the SGML documentation (Bruce)
Unless draft is used, the documentation build will now be repeated if necessary to ensure the index is up-to-date. E.1.3.21. Source Code
Rename macro DLLIMPORT to PGDLLIMPORT to avoid conflicting with third party includes (like Tcl) that define DLLIMPORT (Magnus)
Create "operator families" to improve planning of queries involving cross-data-type comparisons (Tom)
Update GIN extractQuery() API to allow signalling that nothing can satisfy the query (Teodor)
Move NAMEDATALEN definition from postgres_ext.h to pg_config_manual.h (Peter)
Provide strlcpy() and strlcat() on all platforms, and replace error-prone uses of strncpy(), strncat(), etc (Peter)
Create hooks to let an external plugin monitor (or even replace) the planner and create plans for hypothetical situations (Gurjeet Singh, Tom)
Create a function variable join_search_hook to let plugins override the join search order portion of the planner (Julius Stroffek)
Add tas() support for Renesas' M32R processor (Kazuhiro Inaoka)
quote_identifier() and pg_dump no longer quote keywords that are unreserved according to the grammar (Tom)
Change the on-disk representation of the NUMERIC data type so that the sign_dscale word comes before the weight (Tom)
Use SYSV semaphores rather than POSIX on Darwin >= 6.0, i.e., OS X 10.2 and up (Chris Marcellino)
Add acronym and NFS documentation sections (Bruce)
"Postgres" is now documented as an accepted alias for "PostgreSQL" (Peter)
Add documentation about preventing database server spoofing when the server is down (Bruce) E.1.3.22. Contrib
Move contrib README content into the main PostgreSQL documentation (Albert Cervera i Areny)
Add contrib/pageinspect module for low-level page inspection (Simon, Heikki)
Add contrib/pg_standby module for controlling warm standby operation (Simon)
Add contrib/uuid-ossp module for generating UUID values using the OSSP UUID library (Peter)
Use configure --with-ossp-uuid to activate. This takes advantage of the new UUID builtin type.
Add contrib/dict_int, contrib/dict_xsyn, and contrib/test_parser modules to provide sample add-on text search dictionary templates and parsers (Sergey Karpov)
Allow contrib/pgbench to set the fillfactor (Pavan Deolasee)
Add timestamps to contrib/pgbench -l (Greg Smith)
Add usage count statistics to contrib/pgbuffercache (Greg Smith)
Add GIN support for contrib/hstore (Teodor)
Add GIN support for contrib/pg_trgm (Guillaume Smet, Teodor)
Update OS/X startup scripts in contrib/start-scripts (Mark Cotner, David Fetter)
Restrict pgrowlocks() and dblink_get_pkey() to users who have SELECT privilege on the target table (Tom)
Restrict contrib/pgstattuple functions to superusers (Tom)
contrib/xml2 is deprecated and planned for removal in 8.4 (Peter)
The new XML support in core PostgreSQL supersedes this module.
This release contains a variety of fixes from 8.3.0. E.1.1. Migration to Version 8.3.1
A dump/restore is not required for those running 8.3.X. However, you might need to REINDEX indexes on textual columns after updating, if you are affected by the Windows locale issue described below. E.1.2. Changes
Fix character string comparison for Windows locales that consider different character combinations as equal (Tom)
This fix applies only on Windows and only when using UTF-8 database encoding. The same fix was made for all other cases over two years ago, but Windows with UTF-8 uses a separate code path that was not updated. If you are using a locale that considers some non-identical strings as equal, you may need to REINDEX to fix existing indexes on textual columns.
Repair corner-case bugs in VACUUM FULL (Tom)
A potential deadlock between concurrent VACUUM FULL operations on different system catalogs was introduced in 8.2. This has now been corrected. 8.3 made this worse because the deadlock could occur within a critical code section, making it a PANIC rather than just ERROR condition.
Also, a VACUUM FULL that failed partway through vacuuming a system catalog could result in cache corruption in concurrent database sessions.
Another VACUUM FULL bug introduced in 8.3 could result in a crash or out-of-memory report when dealing with pages containing no live tuples.
Fix misbehavior of foreign key checks involving character or bit columns (Tom)
If the referencing column were of a different but compatible type (for instance varchar), the constraint was enforced incorrectly.
Fix possible core dump when re-planning a prepared query (Tom)
This bug affected only protocol-level prepare operations, not SQL PREPARE, and so tended to be seen only with JDBC, DBI, and other client-side drivers that use prepared statements heavily.
Fix possible failure when re-planning a query that calls an SPI-using function (Tom)
Fix failure in row-wise comparisons involving columns of different datatypes (Tom)
In rare cases a session that had just executed a LISTEN might not get a notification, even though one would be expected because the concurrent transaction executing NOTIFY was observed to commit later.
A side effect of the fix is that a transaction that has executed a not-yet-committed LISTEN command will not see any row in pg_listener for the LISTEN, should it choose to look; formerly it would have. This behavior was never documented one way or the other, but it is possible that some applications depend on the old behavior.
Disallow LISTEN and UNLISTEN within a prepared transaction (Tom)
This was formerly allowed but trying to do it had various unpleasant consequences, notably that the originating backend could not exit as long as an UNLISTEN remained uncommitted.
Disallow dropping a temporary table within a prepared transaction (Heikki)
This was correctly disallowed by 8.1, but the check was inadvertently broken in 8.2 and 8.3.
Fix rare crash when an error occurs during a query using a hash index (Heikki)
Fix incorrect comparison of tsquery values (Teodor)
Fix incorrect behavior of LIKE with non-ASCII characters in single-byte encodings (Rolf Jentsch)
Disable xmlvalidate (Tom)
This function should have been removed before 8.3 release, but was inadvertently left in the source code. It poses a small security risk since unprivileged users could use it to read the first few characters of any file accessible to the server.
Fix memory leaks in certain usages of set-returning functions (Neil)
Make encode(bytea, 'escape') convert all high-bit-set byte values into \nnn octal escape sequences (Tom)
This is necessary to avoid encoding problems when the database encoding is multi-byte. This change could pose compatibility issues for applications that are expecting specific results from encode.
Fix input of datetime values for February 29 in years BC (Tom)
The former coding was mistaken about which years were leap years.
Fix "unrecognized node type" error in some variants of ALTER OWNER (Tom)
Avoid tablespace permissions errors in CREATE TABLE LIKE INCLUDING INDEXES (Tom)
Ensure pg_stat_activity.waiting flag is cleared when a lock wait is aborted (Tom)
Fix handling of process permissions on Windows Vista (Dave, Magnus)
In particular, this fix allows starting the server as the Administrator user.
Update time zone data files to tzdata release 2008a (in particular, recent Chile changes); adjust timezone abbreviation VET (Venezuela) to mean UTC-4:30, not UTC-4:00 (Tom)
Fix ecpg problems with arrays (Michael)
Fix pg_ctl to correctly extract the postmaster's port number from command-line options (Itagaki Takahiro, Tom)
Previously, pg_ctl start -w could try to contact the postmaster on the wrong port, leading to bogus reports of startup failure.
Use -fwrapv to defend against possible misoptimization in recent gcc versions (Tom)
This is known to be necessary when building PostgreSQL with gcc 4.3 or later.
Enable building contrib/uuid-ossp with MSVC (Hiroshi Saito)
Fix GiST index corruption due to marking the wrong index entry "dead" after a deletion (Teodor)
This would result in index searches failing to find rows they should have found.
Fix backend crash when the client encoding cannot represent a localized error message (Tom)
We have addressed similar issues before, but it would still fail if the "character has no equivalent" message itself couldn't be converted. The fix is to disable localization and send the plain ASCII error message when we detect such a situation.
Fix possible crash in bytea-to-XML mapping (Michael McMaster)
Fix possible crash when deeply nested functions are invoked from a trigger (Tom)
Improve optimization of expression IN (expression-list) queries (Tom, per an idea from Robert Haas)
Cases in which there are query variables on the right-hand side had been handled less efficiently in 8.2.x and 8.3.x than in prior versions. The fix restores 8.1 behavior for such cases.
Fix mis-expansion of rule queries when a sub-SELECT appears in a function call in FROM, a multi-row VALUES list, or a RETURNING list (Tom)
The usual symptom of this problem is an "unrecognized node type" error.
Fix Assert failure during rescan of an IS NULL search of a GiST index (Teodor)
Fix memory leak during rescan of a hashed aggregation plan (Neil)
Ensure an error is reported when a newly-defined PL/pgSQL trigger function is invoked as a normal function (Tom)
Force a checkpoint before CREATE DATABASE starts to copy files (Heikki)
This prevents a possible failure if files had recently been deleted in the source database.
Prevent possible collision of relfilenode numbers when moving a table to another tablespace with ALTER SET TABLESPACE (Heikki)
The command tried to re-use the existing filename, instead of picking one that is known unused in the destination directory.
Fix incorrect text search headline generation when single query item matches first word of text (Sushant Sinha)
Fix improper display of fractional seconds in interval values when using a non-ISO datestyle in an --enable-integer-datetimes build (Ron Mayer)
Make ILIKE compare characters case-insensitively even when they're escaped (Andrew)
Ensure DISCARD is handled properly by statement logging (Tom)
Fix incorrect logging of last-completed-transaction time during PITR recovery (Tom)
Ensure SPI_getvalue and SPI_getbinval behave correctly when the passed tuple and tuple descriptor have different numbers of columns (Tom)
This situation is normal when a table has had columns added or removed, but these two functions didn't handle it properly. The only likely consequence is an incorrect error indication.
Mark SessionReplicationRole as PGDLLIMPORT so it can be used by Slony on Windows (Magnus)
Fix small memory leak when using libpq's gsslib parameter (Magnus)
The space used by the parameter string was not freed at connection close.
Ensure libgssapi is linked into libpq if needed (Markus Schaaf)
Fix ecpg's parsing of CREATE ROLE (Michael)
Fix recent breakage of pg_ctl restart (Tom)
Ensure pg_control is opened in binary mode (Itagaki Takahiro)
pg_controldata and pg_resetxlog did this incorrectly, and so could fail on Windows.
Update time zone data files to tzdata release 2008i (for DST law changes in Argentina, Brazil, Mauritius, Syria)
Make DISCARD ALL release advisory locks, in addition to everything it already did (Tom)
This was decided to be the most appropriate behavior. This could affect existing applications, however.
Fix whole-index GiST scans to work correctly (Teodor)
This error could cause rows to be lost if a table is clustered on a GiST index.
Fix crash of xmlconcat(NULL) (Peter)
Fix possible crash in ispell dictionary if high-bit-set characters are used as flags (Teodor)
This is known to be done by one widely available Norwegian dictionary, and the same condition may exist in others.
Fix misordering of pg_dump output for composite types (Tom)
The most likely problem was for user-defined operator classes to be dumped after indexes or views that needed them.
Improve handling of URLs in headline() function (Teodor)
Improve handling of overlength headlines in headline() function (Teodor)
Prevent possible Assert failure or misconversion if an encoding conversion is created with the wrong conversion function for the specified pair of encodings (Tom, Heikki)
Fix possible Assert failure if a statement executed in PL/pgSQL is rewritten into another kind of statement, for example if an INSERT is rewritten into an UPDATE (Heikki)
Ensure that a snapshot is available to datatype input functions (Tom)
This primarily affects domains that are declared with CHECK constraints involving user-defined stable or immutable functions. Such functions typically fail if no snapshot has been set.
Make it safer for SPI-using functions to be used within datatype I/O; in particular, to be used in domain check constraints (Tom)
Avoid unnecessary locking of small tables in VACUUM (Heikki)
Fix a problem that sometimes kept ALTER TABLE ENABLE/DISABLE RULE from being recognized by active sessions (Tom)
Fix a problem that made UPDATE RETURNING tableoid return zero instead of the correct OID (Tom)
Allow functions declared as taking ANYARRAY to work on the pg_statistic columns of that type (Tom)
This used to work, but was unintentionally broken in 8.3.
Fix planner misestimation of selectivity when transitive equality is applied to an outer-join clause (Tom)
This could result in bad plans for queries like ... from a left join b on a.a1 = b.b1 where a.a1 = 42 ...
Improve optimizer's handling of long IN lists (Tom)
This change avoids wasting large amounts of time on such lists when constraint exclusion is enabled.
Prevent synchronous scan during GIN index build (Tom)
Because GIN is optimized for inserting tuples in increasing TID order, choosing to use a synchronous scan could slow the build by a factor of three or more.
Ensure that the contents of a holdable cursor don't depend on the contents of TOAST tables (Tom)
Previously, large field values in a cursor result might be represented as TOAST pointers, which would fail if the referenced table got dropped before the cursor is read, or if the large value is deleted and then vacuumed away. This cannot happen with an ordinary cursor, but it could with a cursor that is held past its creating transaction.
Fix memory leak when a set-returning function is terminated without reading its whole result (Tom)
Fix encoding conversion problems in XML functions when the database encoding isn't UTF-8 (Tom)
Fix contrib/dblink's dblink_get_result(text,bool) function (Joe)
Fix possible garbage output from contrib/sslinfo functions (Tom)
Fix incorrect behavior of contrib/tsearch2 compatibility trigger when it's fired more than once in a command (Teodor)
Fix possible mis-signaling in autovacuum (Heikki)
Support running as a service on Windows 7 beta (Dave and Magnus)
Fix ecpg's handling of varchar structs (Michael)
Fix configure script to properly report failure when unable to obtain linkage information for PL/Perl (Andrew)
Make all documentation reference pgsql-bugs and/or pgsql-hackers as appropriate, instead of the now-decommissioned pgsql-ports and pgsql-patches mailing lists (Tom)
Update time zone data files to tzdata release 2009a (for Kathmandu and historical DST corrections in Switzerland, Cuba)
Кроме накопившихся исправлений ошибок, в представленных выпусках исправлено три уязвимости, две неопасные и одна умеренной степени риска:
Локальный пользователь СУБД может организовать выполнение действий с привилегиями администратора базы, используя возможность выполнения операций "RESET ROLE" и "RESET SESSION AUTHORIZATION" в пользовательских функциях, выполняемых с повышенными правами. Проблеме подвержены все поддерживаемые ветки;
Локальный пользователь СУБД может совершить DoS атаку, вызвав завершение работы сервера, попытавшись повторно загрузить библиотеки, находящиеся в директории $libdir/plugins. Проблеме подвержены ветки 8.4, 8.3 и 8.2;
При использовании LDAP аутентификации, в конфигурации допускающей анонимные подключения, возможен вход под заданным пользователем без пароля.
» Нажмите, для открытия спойлера | Press to open the spoiler «
Protect against indirect security threats caused by index functions changing session-local state (Gurjeet Singh, Tom)
This change prevents allegedly-immutable index functions from possibly subverting a superuser's session (CVE-2009-4136).
Reject SSL certificates containing an embedded null byte in the common name (CN) field (Magnus)
This prevents unintended matching of a certificate to a server or client name during SSL validation (CVE-2009-4034).
Fix hash index corruption (Tom)
The 8.4 change that made hash indexes keep entries sorted by hash value failed to update the bucket splitting and compaction routines to preserve the ordering. So application of either of those operations could lead to permanent corruption of an index, in the sense that searches might fail to find entries that are present. To deal with this, it is recommended to REINDEX any hash indexes you may have after installing this update.
Fix possible crash during backend-startup-time cache initialization (Tom)
Avoid crash on empty thesaurus dictionary (Tom)
Prevent signals from interrupting VACUUM at unsafe times (Alvaro)
This fix prevents a PANIC if a VACUUM FULL is cancelled after it's already committed its tuple movements, as well as transient errors if a plain VACUUM is interrupted after having truncated the table.
Fix possible crash due to integer overflow in hash table size calculation (Tom)
This could occur with extremely large planner estimates for the size of a hashjoin's result.
Fix crash if a DROP is attempted on an internally-dependent object (Tom)
Fix very rare crash in inet/cidr comparisons (Chris Mikkelson)
Ensure that shared tuple-level locks held by prepared transactions are not ignored (Heikki)
Fix premature drop of temporary files used for a cursor that is accessed within a subtransaction (Heikki)
Fix memory leak in syslogger process when rotating to a new CSV logfile (Tom)
Fix memory leak in postmaster when re-parsing pg_hba.conf (Tom)
Fix Windows permission-downgrade logic (Jesse Morris)
This fixes some cases where the database failed to start on Windows, often with misleading error messages such as "could not locate matching postgres executable".
Make FOR UPDATE/SHARE in the primary query not propagate into WITH queries (Tom)
For example, in WITH w AS (SELECT * FROM foo) SELECT * FROM w, bar ... FOR UPDATE
the FOR UPDATE will now affect bar but not foo. This is more useful and consistent than the original 8.4 behavior, which tried to propagate FOR UPDATE into the WITH query but always failed due to assorted implementation restrictions. It also follows the design rule that WITH queries are executed as if independent of the main query.
Fix bug with a WITH RECURSIVE query immediately inside another one (Tom)
Fix concurrency bug in hash indexes (Tom)
Concurrent insertions could cause index scans to transiently report wrong results.
Fix incorrect logic for GiST index page splits, when the split depends on a non-first column of the index (Paul Ramsey)
Fix wrong search results for a multi-column GIN index with fastupdate enabled (Teodor)
Fix bugs in WAL entry creation for GIN indexes (Tom)
These bugs were masked when full_page_writes was on, but with it off a WAL replay failure was certain if a crash occurred before the next checkpoint.
Don't error out if recycling or removing an old WAL file fails at the end of checkpoint (Heikki)
It's better to treat the problem as non-fatal and allow the checkpoint to complete. Future checkpoints will retry the removal. Such problems are not expected in normal operation, but have been seen to be caused by misdesigned Windows anti-virus and backup software.
Ensure WAL files aren't repeatedly archived on Windows (Heikki)
This is another symptom that could happen if some other process interfered with deletion of a no-longer-needed file.
Fix PAM password processing to be more robust (Tom)
The previous code is known to fail with the combination of the Linux pam_krb5 PAM module with Microsoft Active Directory as the domain controller. It might have problems elsewhere too, since it was making unjustified assumptions about what arguments the PAM stack would pass to it.
Raise the maximum authentication token (Kerberos ticket) size in GSSAPI and SSPI authentication methods (Ian Turner)
While the old 2000-byte limit was more than enough for Unix Kerberos implementations, tickets issued by Windows Domain Controllers can be much larger.
Ensure that domain constraints are enforced in constructs like ARRAY[...]::domain, where the domain is over an array type (Heikki)
Fix foreign-key logic for some cases involving composite-type columns as foreign keys (Tom)
Ensure that a cursor's snapshot is not modified after it is created (Alvaro)
This could lead to a cursor delivering wrong results if later operations in the same transaction modify the data the cursor is supposed to return.
Fix CREATE TABLE to properly merge default expressions coming from different inheritance parent tables (Tom)
This used to work but was broken in 8.4.
Re-enable collection of access statistics for sequences (Akira Kurosawa)
This used to work but was broken in 8.3.
Fix processing of ownership dependencies during CREATE OR REPLACE FUNCTION (Tom)
Fix incorrect handling of WHERE x=x conditions (Tom)
In some cases these could get ignored as redundant, but they aren't — they're equivalent to x IS NOT NULL.
Fix incorrect plan construction when using hash aggregation to implement DISTINCT for textually identical volatile expressions (Tom)
Fix Assert failure for a volatile SELECT DISTINCT ON expression (Tom)
Fix ts_stat() to not fail on an empty tsvector value (Tom)
Make text search parser accept underscores in XML attributes (Peter)
Fix encoding handling in xml binary input (Heikki)
If the XML header doesn't specify an encoding, we now assume UTF-8 by default; the previous handling was inconsistent.
Fix bug with calling plperl from plperlu or vice versa (Tom)
An error exit from the inner function could result in crashes due to failure to re-select the correct Perl interpreter for the outer function.
Fix session-lifespan memory leak when a PL/Perl function is redefined (Tom)
Ensure that Perl arrays are properly converted to PostgreSQL arrays when returned by a set-returning PL/Perl function (Andrew Dunstan, Abhijit Menon-Sen)
This worked correctly already for non-set-returning functions.
Fix rare crash in exception processing in PL/Python (Peter)
Fix ecpg problem with comments in DECLARE CURSOR statements (Michael)
Fix ecpg to not treat recently-added keywords as reserved words (Tom)
This affected the keywords CALLED, CATALOG, DEFINER, ENUM, FOLLOWING, INVOKER, OPTIONS, PARTITION, PRECEDING, RANGE, SECURITY, SERVER, UNBOUNDED, and WRAPPER.
Re-allow regular expression special characters in psql's \df function name parameter (Tom)
In contrib/pg_standby, disable triggering failover with a signal on Windows (Fujii Masao)
This never did anything useful, because Windows doesn't have Unix-style signals, but recent changes made it actually crash.
Put FREEZE and VERBOSE options in the right order in the VACUUM command that contrib/vacuumdb produces (Heikki)
Fix possible leak of connections when contrib/dblink encounters an error (Tatsuhito Kasahara)
Ensure psql's flex module is compiled with the correct system header definitions (Tom)
This fixes build failures on platforms where --enable-largefile causes incompatible changes in the generated code.
Make the postmaster ignore any application_name parameter in connection request packets, to improve compatibility with future libpq versions (Tom)
Update the timezone abbreviation files to match current reality (Joachim Wieland)
This includes adding IDT to the default timezone abbreviation set.
Update time zone data files to tzdata release 2009s for DST law changes in Antarctica, Argentina, Bangladesh, Fiji, Novokuznetsk, Pakistan, Palestine, Samoa, Syria; also historical corrections for Hong Kong.
Add new configuration parameter ssl_renegotiation_limit to control how often we do session key renegotiation for an SSL connection (Magnus)
This can be set to zero to disable renegotiation completely, which may be required if a broken SSL library is used. In particular, some vendors are shipping stopgap patches for CVE-2009-3555 that cause renegotiation attempts to fail.
Fix possible deadlock during backend startup (Tom)
Fix possible crashes due to not handling errors during relcache reload cleanly (Tom)
Fix possible crash due to use of dangling pointer to a cached plan (Tatsuo)
Fix possible crash due to overenthusiastic invalidation of cached plan for ROLLBACK (Tom)
Fix possible crashes when trying to recover from a failure in subtransaction start (Tom)
Fix server memory leak associated with use of savepoints and a client encoding different from server's encoding (Tom)
Fix incorrect WAL data emitted during end-of-recovery cleanup of a GIST index page split (Yoichi Hirai)
This would result in index corruption, or even more likely an error during WAL replay, if we were unlucky enough to crash during end-of-recovery cleanup after having completed an incomplete GIST insertion.
Fix bug in WAL redo cleanup method for GIN indexes (Heikki)
Fix incorrect comparison of scan key in GIN index search (Teodor)
Make substring() for bit types treat any negative length as meaning "all the rest of the string" (Tom)
The previous coding treated only -1 that way, and would produce an invalid result value for other negative values, possibly leading to a crash (CVE-2010-0442).
Fix integer-to-bit-string conversions to handle the first fractional byte correctly when the output bit width is wider than the given integer by something other than a multiple of 8 bits (Tom)
Fix some cases of pathologically slow regular expression matching (Tom)
Fix bug occurring when trying to inline a SQL function that returns a set of a composite type that contains dropped columns (Tom)
Fix bug with trying to update a field of an element of a composite-type array column (Tom)
Avoid failure when EXPLAIN has to print a FieldStore or assignment ArrayRef expression (Tom)
These cases can arise now that EXPLAIN VERBOSE tries to print plan node target lists.
Avoid an unnecessary coercion failure in some cases where an undecorated literal string appears in a subquery within UNION/INTERSECT/EXCEPT (Tom)
This fixes a regression for some cases that worked before 8.4.
Avoid undesirable rowtype compatibility check failures in some cases where a whole-row Var has a rowtype that contains dropped columns (Tom)
Fix the STOP WAL LOCATION entry in backup history files to report the next WAL segment's name when the end location is exactly at a segment boundary (Itagaki Takahiro)
Always pass the catalog ID to an option validator function specified in CREATE FOREIGN DATA WRAPPER (Martin Pihlak)
Fix some more cases of temporary-file leakage (Heikki)
This corrects a problem introduced in the previous minor release. One case that failed is when a plpgsql function returning set is called within another function's exception handler.
Add support for doing FULL JOIN ON FALSE (Tom)
This prevents a regression from pre-8.4 releases for some queries that can now be simplified to a constant-false join condition.
Improve constraint exclusion processing of boolean-variable cases, in particular make it possible to exclude a partition that has a "bool_column = false" constraint (Tom)
Prevent treating an INOUT cast as representing binary compatibility (Heikki)
Include column name in the message when warning about inability to grant or revoke column-level privileges (Stephen Frost)
This is more useful than before and helps to prevent confusion when a REVOKE generates multiple messages, which formerly appeared to be duplicates.
When reading pg_hba.conf and related files, do not treat @something as a file inclusion request if the @ appears inside quote marks; also, never treat @ by itself as a file inclusion request (Tom)
This prevents erratic behavior if a role or database name starts with @. If you need to include a file whose path name contains spaces, you can still do so, but you must write @"/path to/file" rather than putting the quotes around the whole construct.
Prevent infinite loop on some platforms if a directory is named as an inclusion target in pg_hba.conf and related files (Tom)
Fix possible infinite loop if SSL_read or SSL_write fails without setting errno (Tom)
This is reportedly possible with some Windows versions of openssl.
Disallow GSSAPI authentication on local connections, since it requires a hostname to function correctly (Magnus)
Protect ecpg against applications freeing strings unexpectedly (Michael)
Make ecpg report the proper SQLSTATE if the connection disappears (Michael)
Fix translation of cell contents in psql \d output (Heikki)
Fix psql's numericlocale option to not format strings it shouldn't in latex and troff output formats (Heikki)
Fix a small per-query memory leak in psql (Tom)
Make psql return the correct exit status (3) when ON_ERROR_STOP and --single-transaction are both specified and an error occurs during the implied COMMIT (Bruce)
Fix pg_dump's output of permissions for foreign servers (Heikki)
Fix possible crash in parallel pg_restore due to out-of-range dependency IDs (Tom)
Fix plpgsql failure in one case where a composite column is set to NULL (Tom)
Fix possible failure when calling PL/Perl functions from PL/PerlU or vice versa (Tim Bunce)
Add volatile markings in PL/Python to avoid possible compiler-specific misbehavior (Zdenek Kotala)
Ensure PL/Tcl initializes the Tcl interpreter fully (Tom)
The only known symptom of this oversight is that the Tcl clock command misbehaves if using Tcl 8.5 or later.
Prevent ExecutorEnd from being run on portals created within a failed transaction or subtransaction (Tom)
This is known to cause issues when using contrib/auto_explain.
Prevent crash in contrib/dblink when too many key columns are specified to a dblink_build_sql_* function (Rushabh Lathia, Joe Conway)
Allow zero-dimensional arrays in contrib/ltree operations (Tom)
This case was formerly rejected as an error, but it's more convenient to treat it the same as a zero-element array. In particular this avoids unnecessary failures when an ltree operation is applied to the result of ARRAY(SELECT ...) and the sub-select returns no rows.
Fix assorted crashes in contrib/xml2 caused by sloppy memory management (Tom)
Make building of contrib/xml2 more robust on Windows (Andrew)
Fix race condition in Windows signal handling (Radu Ilie)
One known symptom of this bug is that rows in pg_listener could be dropped under heavy load.
Make the configure script report failure if the C compiler does not provide a working 64-bit integer datatype (Tom)
This case has been broken for some time, and no longer seems worth supporting, so just reject it at configure time instead.
Update time zone data files to tzdata release 2010e for DST law changes in Bangladesh, Chile, Fiji, Mexico, Paraguay, Samoa.
редставлено более 200 улучшений. PostgreSQL 9.0 является первым релизом со встроенной системой бинарной репликации в режиме реального времени, позволяющей организовать горячее резервное копирование и потоковую репликацию.
Ключевые улучшения:
* Реализация режима "горячего резерва" (Hot Standby), при котором появилась возможность выполнения select запросов на запасном сервере, т.е. теперь можно штатными средствами организовать master-slave репликацию с практически нулевой дополнительной нагрузкой на сервер (с master сервера просто копируются WAL-логи (write-ahead logging), без каких-либо блокировок и дополнительного вызова триггеров). Ранее синхронизированный сервер не мог выполнять запросы, и находился в неактивном режиме, при котором он мог только перехватить управление в случае сбоя основного сервера; * Поддержка режима потоковой репликации (Streaming Replication), суть которой в организации непрерывной передачи бинарных WAL-логов нескольким запасным серверам PostgreSQL; * Поддержка 64-разрядной версии для платформы Windows; * Замена pg_listener на новый работающий в памяти механизм Listen/Notify, ориентированный на высокопроизводительный обмен сообщениями и обслуживание очередей. Listen/Notify реализован в виде очереди событий в оперативной памяти, вместо таблицы; * Для автоматизации обновления базы при переходе на более новую ветку PostgreSQL (с 8.3 или 8.4 до 9.0) добавлена утилита pg_upgrade; * Через оператор "DO" теперь можно выполнять код в SQL-выражении на процедурном языке без создания отдельной функции. Директива "DO" теперь поддерживает ad-hoc и "anonymous" блоки; * Возможность назначать триггеры для отдельных столбцов и выполнять триггеры по условиям; * По умолчанию теперь активируется встроенный язык PL/pgSQL. Переработан парсер PL/pgSQL. Разнообразные улучшения также добавлены в реализации PL/Perl и PL/Python, например, добавлена поддержка Python 3; * Добавлены "исключающие ограничения", представляющие собой обобщенный аналог UNIQUE и реализующие новые способы гарантии логической целостности данных в базе. Возможность задания флага DEFERRABLE для выражений с признаком UNIQUE (отложенная UNIQUE-проверки); * Улучшена поддержка хранения в одном поле произвольного набора данных в формате ключ/значение; * В оптимизаторе появились средства для автоматического удаления лишних JOIN-ов и оптимизации для ORM-запросов (object relational mapper). * Автоматический возврат числа строк, фигурирующих в выполненном SELECT-запросе. В psql данное значение не отображается, но может быть получено с использованием программного интерфейса, подобного libpq. * Поддержка функций ROWS PRECEDING и ROWS FOLLOWING в WINDOW-блоке SELECT-запроса, позволяющих сформировать кадр из заданного числа строк, относительно текущей позиции. * Использование блока ORDER BY внутри агрегатных функций (например: array_agg(a ORDER BY ), теперь не нужно прибегать к ухищрениям для получения упорядоченного набора записей на входе агрегатных функций; * Добавлена возможность контроля доступа к большим объектам (large objects); * В функции регулярных выражений добавлена поддержка независимых от регистра проверок и классификации символов, привязанной к текущей локализации, при использовании кодировки UTF8 на сервере; * Для упрощения разграничения доступа для множества объектов реализованы конструкции "GRANT ALL ON" и "ALTER DEFAULT PRIVILEGES". Добавлена поддержка установки прав для BLOB-ов (больших бинарных объектов); * Возможность использования именованных параметров в функциях; * Поддержка отложенных проверок уникальных ключей; * Поддержка конструкции IF EXISTS в DROP COLUMN/CONSTRAINT; * Возможность вывода результатов работы EXPLAIN в YAML, XML и JSON форматах; * Новый шестнадцатиричный формат ввода и вывода для типа данных BYTEA; * Новые возможности безопасности - аутентификация через RADIUS, улучшения в LDAP, модуль проверки стойкости паролей "passwordcheck"; * Улучшения в "hstore", включая новые функции и поддержка данных большого размера; * Новая реализация VACUUM FULL, полностью перезаписывающая таблицы и индексы, что быстрее и эффективнее в большинстве случаев, чем перемещение отдельных строк для повышения компактности хранилища; * Поддержка многопоточности в утилите pgbench, что позволяет задействовать все CPU в системе и сгенерировать более реалистичную тестовую нагрузку. Downloads (~13,1 Mb)_http://wwwmaster.post...-9.0.0.tar.bz2
ЭЖД, 6.10.2010 - 17:35
PostgreSQL 9.0.1
Устранено 10 ошибок, отдельно отмечается устранение проблемы безопасности: # Аутентифицированный пользователь СУБД с доверительными правами ("trusted") запуска хранимых процедур мог манипулировать содержимом модулей и связанных-переменных в функциях на языках PL/Perl и PL/Tcl, что можно использовать для организации выполнения кода с привилегиями другого пользователя, использующего функции с атрибутом "SECURITY DEFINER". Также сообщается, что проблеме подвержены функции на PL/PHP и других процедурных языках, исправление для PL/PHP пока недоступно, но будет выпущено в ближайшее время.
Некоторые из наиболее серьезных исправлений:
* Устранен крах при выполнении функции show_session_authorization() в момент выполнения операции autovacuum; * Решена проблема с утечкой соединений после двойного указания некорректного имени соединения. Налажена обработка имен соединений длиннее 63 байт. Улучшена работа contrib/dblink для таблиц с удаленными столбцами; * Добавлена защита от возвращения функциями setof-записи, когда не все возвращаемые строки имеют идентичный тип столбцов. Ошибка свойственна только 8.0 и более ранним веткам; * Устранено возможное дублирование сканирования связей для выражения UNION ALL. Ошибка свойственна только 8.2 и более ранним веткам; * Возникновение фатального состояния (PANIC) сведено до вывода ошибки (ERROR) в случае редкого возникновения проблем с btree. Ошибка свойственна только 8.2 и более ранним веткам; * В contrib/hstore добавлена функция hstore(text, text), позволяющая уйти от использования оператора "=>", который объявлен устаревшим в ветке 9.0. Изменение затрагивает только 8.2 и более ранние ветки; * Исправлена проблема с пометкой прокешированных планов как скоротечных, что приводило к неправильному использованию CREATE INDEX CONCURRENTLY. Ошибка свойственна только 8.3 и более ранним веткам; * Исправлена ошибки вычисления внутренней составляющей внешней JOIN-операции, являющейся подзапросом с нестрогим выражением в выходном списке. Изменение затрагивает только 8.4 и более ранние ветки; * Добавлена поддержка удачной полной верификации SSL-сертификата, в случае когда одновременно указаны и имя и адрес хоста (host и hostaddr). Изменение затрагивает только 8.4 и более ранние ветки; * Улучшена возможность по параллельному восстановлению в случае указания выборочных опций ("restore -L"). Изменение затрагивает только 8.4 и более ранние ветки; * Решена проблема, когда запрос "ALTER TABLE t ADD COLUMN c serial" выполняет не владелец таблицы. Изменение затрагивает только ветку 9.0. Downloads (~13,4 Mb)_ftp://ftp.postgresql...-9.0.1.tar.bz2
ЭЖД, 16.12.2010 - 21:46
PostgreSQL 9.0.2
Устранено 79 ошибок. Отдельно подчеркивается важность проведения обновления пользователям использующим режим "теплого" резервного копирования на запасной сервер (Warm Standby) или проводящим восстановление состояния базы на определенный момент времени (Point-In-Time Recovery), так как могут наблюдаться проблемы с восстановлением данных из WAL-логов.
Из других исправлений можно отметить утечки памяти при выполнении операции ANALYZE для сложных индексов, при использовании функций contrib/xml2 и при работе autovacuum. Исправлено несколько ошибок, приводящих к краху рабочего процесса при достаточно редких обстоятельствах. Устранено переполнение буфера в утилите pg_upgrade. Увеличена производительность параллельного восстановления баз с большим числом бинарных объектов (blob). Downloads (~13,6 Mb)_ftp://ftp.postgresql...-9.0.2.tar.bz2

 PostgreSQL 8.0.3
PostgreSQL 8.0.3 WIDTH=305 align="left">Что такое PostgreSQL ?
WIDTH=305 align="left">Что такое PostgreSQL ?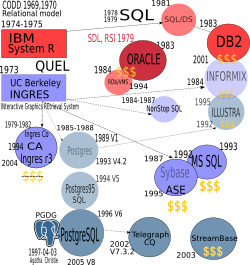
 ), теперь не нужно прибегать к ухищрениям для получения упорядоченного набора записей на входе агрегатных функций;
), теперь не нужно прибегать к ухищрениям для получения упорядоченного набора записей на входе агрегатных функций;